How it works
Our attention mechanism is a drop-in replacement of the scaled dot-product attention found in large language models.
Imagine being able to pre-train large language models within a more reasonable budget, without having to worry about the attention fading problem that comes with large context lengths.
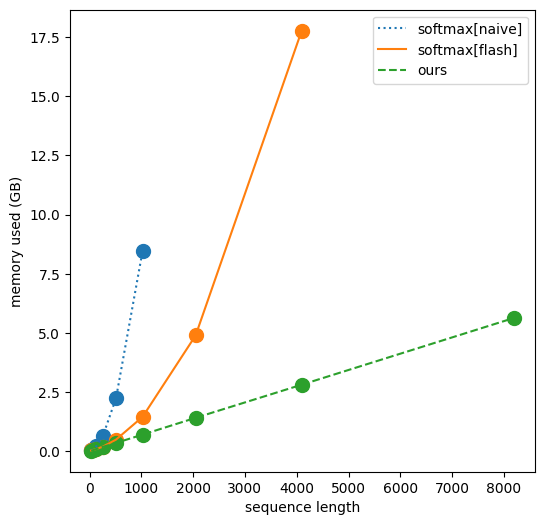
True linear attention - both the memory and compute requirements scale linearly - in both the token dimension and the context length.